





jueves 6 abril 2023
La Dra. Nadia Mery es una de las nueve investigadoras que se incorporaron el año pasado al Advanced Mining Technology Center de la Universidad de Chile a través de su Programa de Atracción de Investigadoras. En concreto, mediante el concurso de financiamiento para proyectos de ejecución rápida (también llamados “proyectos semilla” por su potencial de proyección) que el Centro abrió exclusivamente para investigadoras. Desde agosto de 2022 ella se encuentra trabajando en un proyecto que tiene a la geoestadística como eje.
Nadia Mery recibió en 2015 su título de ingeniera civil de minas en la Universidad de Chile, con especialidad en geoestadística, para luego hacer un magíster en las mismas casa de estudios y disciplina, programa que terminó con éxito en 2016. Tras dichos estudios se desempeñó como ingeniera de producción en Codelco. De 2017 a 2022 fue estudiante de doctorado en geoestadística y aprendizaje de máquina en la universidad Politécnica de Montreal y en 2022 se incorporó al Departamento de Ingeniería de Minas de la Universidad de Chile como profesora asistente y al AMTC como investigadora de proyecto semilla.
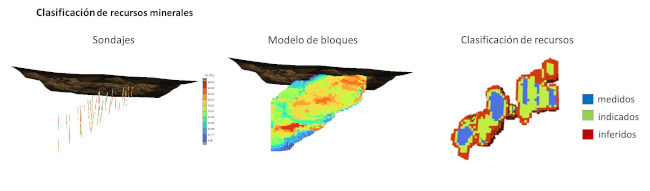
Lo que la Dra. Mery quiere resolver con su proyecto es la subjetividad del proceso de categorización de recursos minerales y la falta de incorporación de incertidumbre en este mismo proceso. “Actualmente”, explica la investigadora, “el proceso de categorización depende casi en su totalidad de una persona denominada persona competente o calificada, quien tiene la potestad de decidir en función de su expertise y conocimiento cuál será el criterio considerado para definir los recursos minerales en las categorías de medidos, indicados e inferidos, donde el nivel de confianza geológica disminuye respectivamente. Frente a esta situación mi proyecto de investigación busca proponer un enfoque alternativo capaz de incorporar la incertidumbre como factor de decisión al momento de definir las categorías de los recursos, lo cual es un input muy importante a lo largo de todo proceso minero, en especial para la definición de las reservas mineras”.
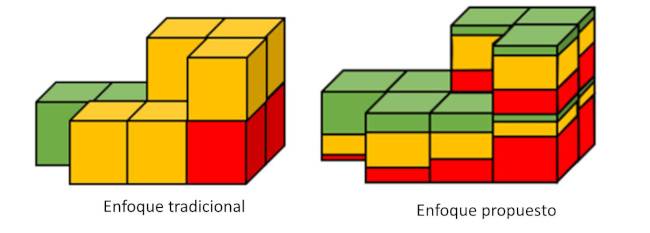
En concreto, este proyecto busca utilizar un enfoque probabilístico basado en simulaciones geoestadísticas para generar múltiples realizaciones de los recursos minerales de un yacimiento. Con estas realizaciones es posible definir ciertos niveles de confianza que permiten asignarle a cada bloque un porcentaje de cada categoría. “Es decir, cada bloque podría tener una fracción medida, otra indicada y otra inferida. Esta propuesta va en línea con dos aspectos claves del proceso de categorización, ya que en primer lugar incorpora la incertidumbre en el proceso de clasificación y en segundo lugar cumple con las normativas y lineamientos generales de los códigos internacionales”, profundiza la Dra. Mery.
Este procedimiento podría mejorar significativamente la toma de decisiones en ámbitos como el diseño de una mina y la planificación de operaciones. Una mejor caracterización de los recursos puede reducir de forma notoria la incertidumbre en los procesos agua debajo de los proyectos mineros, dice la académica: «Tener en consideración la incertidumbre en la definición de las categorías de los recursos minerales permite en términos simples anticiparse a eventuales fluctuaciones o variabilidades futuras y en consecuencia mejores decisiones pueden ser tomadas hoy para evitar los problemas futuros”.
El proyecto de la Dra. Mery ya ha avanzado en todo el desarrollo teórico y la programación de rutinas computacionales. Además ya se tienen los primeros resultados de un caso de estudio en un yacimiento ferrífero y actualmente se está iniciando el trabajo de un segundo caso de estudio en una veta. La investigadora espera que en un corto plazo los principales resultados de su proyecto sean publicados en una revista internacional y que en el largo plazo la metodología que propone sea adoptada por la industria minera como una alternativa factible al momento de categorizar recursos minerales.